漫谈DevOps和SRE
06 Aug 2021 . . Comments #DevOps #SRE
漫谈DevOps 和 SRE
这篇随想是记录了我对于devops和sre方法论的一些思考。 作为一个it从业人员,我在自
称为SRE的团队里面工作了十多年,和DevOps社区,以及从业人员也有非常紧密的接触。这
些观点写下来,表达一下对于这个行业的一些看法,以及为什么认为SRE才是DevOps的最佳
实践
什么是Devops
如果你问一个公司,DevOps到底是怎么做的,不同的公司可能会有非常不一样的答案。其
原因也非常简单,就是业界没有一个标准的DevOps的定义。维基百科上定义DevOps为:
DevOps is a set of practices that combines software development (Dev) and IT operations (Ops), 而亚马逊定义DevOps为: the combination of cultural philosophies, practices and tools that increases an organization’s ability to deliver applications and services at high velocity.甚至都没有提到开发和运维字眼,而就是定义了一系列为了加速application delivery的
工具和文化的合集。这种不一致和模糊也导致了全世界的产品都管自己是DevOps工具:
puppet是,docker是,splunk是,promethuse是,连git都是DevOps tool。究其原因,大
约是靠上DevOps这个火热的概念产品会比较好卖吧。
从现在DevOps概念上的趋势来看,它实际上是希望能够涵盖applicaiton 整个生命周期的
管理,但是Dev+Ops的命名在天然上有它的劣势,让人感觉只是开发和运维,而在开发之前
,需求管理,设计都不在概念之内。 所以现在对整个概念的理解,广度上不够广,很多人
认为Agile不在DevOps里面。然而它又不够窄,没有明确的说明Devops的重点问题。于是导
致了每个人理解的不一致。
从DevOps的最原始的定义来说,它存在的目的就是为了打破开发和运维之间的部门墙。经
典的描述DevOps部门墙的图片如下:

这张图片描述了一个传统做法会出现的问题,一般来说传统的做法是,开发将代码开发完毕之后,将打包后的artifacts,或者干脆不打包,直接 将源代码丢给Ops,让他们进行部署和运维,开发人员一般没有权限对生产环境进行任何操 作。我们描述Dev和Ops之间的冲突,经常归类于Dev想快速发布而Ops想维持稳定。实际上 我认为这个描述是有误的,Ops不是想维持稳定而不支持Dev进行迭代,问题出在技能的 gap上. Ops的技能是运维infrastructure,比如linux, network,而不是业务的代码。当 app出问题的时候,由于开发人员不能很容易的访问生产的环境,对发生的事情不清楚,而 Ops也不熟悉app代码,导致问题出现,双方互相指责,从而形成很高的部门壁垒。
DevOps认为解决Dev和Ops的部门墙的最佳做法是将Ops的责任左移。原来由infrastructure
Ops承担的大部分应用运维的责任,应该由开发团队自己承担,一句话来总结这个原则,那
就是:谁开发,谁运维。这里面就包括了
- 对应用的发布
- 对应用的监控
- 对事故的响应和处理
CI/CD
当前,CI/CD 是DevOps中处理应用发布的标准做法,然而对应用发布的过分强调导致了
DevOps运动中最大的误解:DevOps就是CI/CD,大部分公司的DevOps工程师做的工作也是
CI/CD工具链的搭建。Azure甚至把他们CI/CD的产品直接叫做Azure DevOps,在我看来实属
过分。CICD分为两个部分,持续集成和持续发布/部署。很显然,持续集成完全是一个开发
团队内部问题,不需要Ops的参与,而且业界的方法也大同小异,无非是单元测试, 代码
扫描,应用打包这几个步骤。对应用的发布,传统上是Ops的工作,在DevOps的情景下,
这部分责任转移到了开发团队。
不过CI/CD并不能定义DevOps,诚然,DevOps的工具链需要Ops维护,这也是大部分公司里
面DevOps团队的责任,维护一套工具,支持开发团队的持续交付和持续部署。但我认为
这部分工作的价值,不能单独撑起一个DevOps团队的旗号。假如我们买了Azure DevOps来
做CICD,那是不是就不需要专门的DevOps团队了?
日志和监控
左移的Ops工作另外一个就是监控,日志是监控的一个部分。成熟的DevOps体系中应该提供 这样的监控平台,告诉开发人员,其应用当前的状态,并对历史状态进行追溯。
成熟的监控体系应该有如下的几个层级,
- 基础设施监控,包括服务器,db,容器等,一般推荐使用USE method
- 应用监控,包括应用本身相关的api,健康状态,分布式追踪等。
- 业务流程监控,这是对应用所支撑的业务的整体流程的监控体系,这也是业务人员最关 注的部分。
开发团队应该对应用和流程的监控进行响应,这一点看起来非常合情合理。 但是 infrastructure的ownership定位不同会导致团队合作的一系列问题。
如果秉承传统的做法, 开发只关注应用,由运维团队统一管理infrastructure的监控 ,那么依然有很大可能,会造成开发和运维之间的相互甩锅。 在这种模式下,两个团队依然没有统一的价值观。运维的责任是运维基础设施,开发的 责任是运维应用。然而基础设施和应用是融合的,它们之间相互影响。应用本身不合理 ,会导致基础设施的崩溃,反之亦然。没有一个full pic的观测体系,首先会影响问题的定 位,造成大量的时间,人力的浪费。如果是开发的问题,那么运维会认为,不是自己的 问题,也被loop到了整个事故中加班加点,产生怨气,从而导致部门之间互相指责。本人 团队里面就出现过这样的现象,由于开发代码的一个bug,暂用了大量网络套接字而导致服 务器网络资源耗尽,在问题的调试阶段,开发团队认为是网络问题,对平台团队诸多质疑 ,造成合作上的紧张。
我们显然不能将infra的责任全部扔给开发团队,首先开发的主要责任还是实现业务代 码,其次技能也有很大的gap。在DevOps的场景下,提倡的是开发运维一体化,也就是 将运维的责任,加入到开发团队,所有infra和app的运维都是为了稳定高效的提供业务 价值。在这样一个全职能团队的情况下,infra运维的目的也是支持应用的稳定。
如何设置这样的团队是一个很大的挑战。一般来说,infra的变化不如应用快速, 那么我 们不应该在每个开发团队里面专职的infra运维。而应该是一个运维人员对多个应用负责
SRE的做法
SRE(site reliability engineering)是 google 提出的一个稳定性管理的理论,其主要
精华在于使用software engineer的方式来管理和运维应用,并提供了一系列操作实践。
Google 认为SRE是一种DevOps文化的的具体实践,从这里一点上,我个人是比较认同的。
这套理论有一系列的工程化实践,比如拥抱风险,Service Level Objective,Automation ,监控等。但是我觉得这套理论的精华,还是从软件工程师的思维管理运维,从而促进两 个团队的融合。
SRE团队的第一思路就是让软件工程师去全职管理运维问题,这样做有几个好处
- 由于软件工程师天然的特性,它们会对那些重复的,手工工作感到厌倦,同时由于他们有相关的开发能力,那么他们就会自然的写一些工具,来替代那些手工工作。提高运维的能力和效率
- 由于开发思维的一致性,运维团队和开发团队对产品的发布和管理有同样的理解。这种理解可以很大程度上解决传统开发和运维在思维模式上造成的冲突问题。
但是设置 SRE 团队也有很大的挑战
- SRE 开发人员的技能要求是什么?
Operation 不是一个简单的开发问题,除了编程能力,对传统的系统管理
(Linux/Unix)都有相关的技能要求,而这些技能在传统开发里面,是比较稀缺的, 从而导致招聘相应的SRE工程师,在市场上非常困难。这些技能的补充一般可以通过1)在SRE team中招聘传统的系统管理员,2)或者通过对 开发人员进行培训来获得。不过#2比较困难,我个人推荐#1,通过在SRE中设置相关的 岗位,招聘相应的人员一起工作来解决技能的gap。 . - 如何和应用开发团队进行合作? 业界 SRE和应用团队的合作模式有两种:集中式的
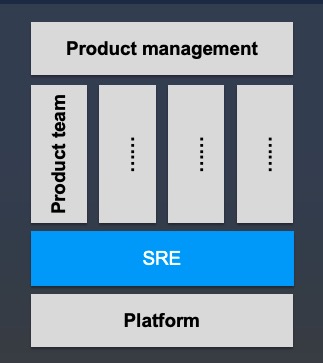
和嵌入式的SRE。集中式的SRE团队设置如下图所示,facebook使用的就是这样的模
式,通过设置一个中心化的product engineering 团队来解决运维问题。
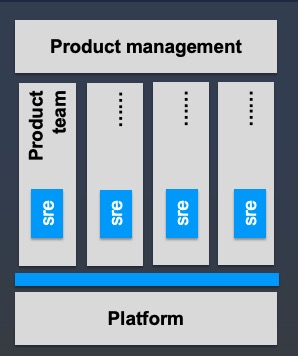
 更加常见的的做法是嵌入式的SRE团队,Google,Uber使用的都是这样的模式。一个
SRE工程师是应用团队里面的一员,他参与到应用的设计开发,可以直接更改应用的代
码,帮助解决应用的稳定性问题。当应用团队比较成熟的时候,rotate到另外一个团队
。
更加常见的的做法是嵌入式的SRE团队,Google,Uber使用的都是这样的模式。一个
SRE工程师是应用团队里面的一员,他参与到应用的设计开发,可以直接更改应用的代
码,帮助解决应用的稳定性问题。当应用团队比较成熟的时候,rotate到另外一个团队
。
在我的工作中,一直使用的是集中式的SRE团队管理模式,深刻感觉到这种模式在沟通存在天然 的缺陷。 SRE定义的稳定性的标准,很难顺畅的delivery到应用团队。所以个人比较推荐 嵌入式的SRE团队,将工程师直接植入到开发团队里面,通过一层比较薄的管理层来管理 SRE团队和工作。当前所有的公司,基本上都有一个平台团队,有包括管理工具链和 infrastructure的责任,那么SRE应该是这个团队里面的一员,起到承上启下的作用。
除此之外,还有一个感触是将传统的系统管理员团队培养成SRE非常困难。很多人将学会
infrastructure as code, ansible, puppet,简单的脚本开发当成SRE的充足条
件。这些其实只是系统管理员的一个简单升级版而已。要打造一个SRE团队,一定要有充分
的软件开发,架构能力,才能设计足够robust的系统,能够优雅的解决运维问题。因此,
打造SRE必须对原有团队进行一个破坏性的重建,补充很好的开发工程师,释放一些不需要
的资源,才能迅速达到建设的目的。